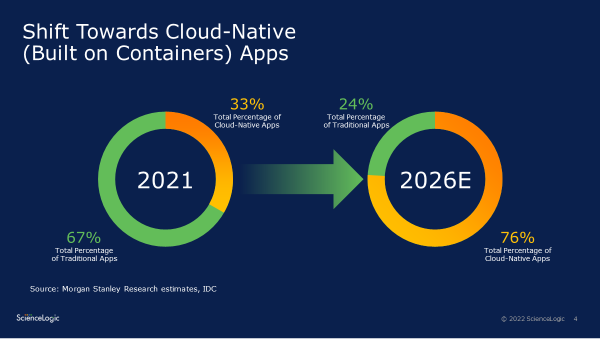
Adding more detail to Gartner’s forecast, financial services firm Morgan Stanley expects that the total number of enterprise applications will almost quadruple from 147 million in 2021 to 582 million in 2026, a 32% compound annual growth rate. At the same time, Morgan Stanley believes the share of cloud-native apps will grow from 33% in 2021 to 76% in 2026.
That’s good news for enterprises that will benefit from more choices, lower operating costs, and greater operational and technical flexibility; but it comes with challenges for IT operations teams who will have to contend with a corresponding and significant increase in the effort required to understand application performance and assure business services and user experiences.
Because of the sheer volume, variety, and velocity of data these systems generate, it is not possible for humans to both see and put that data into context, much less derive actionable insights for accelerating, augmenting, and automating ITOps. And since many larger organizations’ applications and infrastructure will remain in data centers for years to come, they’ll also have to monitor, troubleshoot, and assure these new cloud-native technologies in the context of their legacy applications and infrastructure, or risk creating new data silos rather than tearing them down.
An Ominous Prospect
This is an ominous prospect for IT operations. Legacy IT monitoring and management platforms are already unable to keep up with current demands; they will be useless when confronted with increased complexity and data volumes that are orders of magnitude higher than they contend with now. Even newer tools engineered for cloud-native technologies, like application performance monitoring (APM) platforms, will have challenges. These rely on the observability of metrics, events, logs, and traces (MELT) that help developers and DevOps practitioners in born-in-the-cloud organizations better comprehend the performance of modern applications.
But in that near future scenario of massive data generation, the platforms that will become the workhorses for IT operations monitoring and management are those that transcend simple observability to deliver an understanding of application and business service performance within the context of a company’s larger IT estate and leverage machines to derive the insights that rely on humans today. These platforms will need to ingest both cloud-native data and look across traditional systems and infrastructure to deliver a complete, unified understanding of the health of that estate. And platforms should remove the reliance on humans with machine-driven insights and automated actions to satisfy end user—customer and employee—expectations and achieve desired business outcomes.
That is why ScienceLogic is focused on extending our SL1 AIOps platform with “observability insights” that leverage our ability to See, Contextualize, and Act, treating cloud-native applications as first-class citizens of the IT estate. Using a combination of targeted insights and root cause insights, SL1 will enable our customers to understand their business services regardless of whether their applications and infrastructure are on-premises, hybrid-cloud deployed, multi-cloud deployed, or cloud-native.
More and Better Insights
Here’s more detail on what we mean by targeted and root cause insights:
Targeted Insights – Every large enterprise, service provider, and government organization is operating a set of tools targeted at monitoring the performance of applications – both cloud-native and otherwise. Rather than asking customers and prospects to implement yet another APM or observability tool that:
- Overlaps with their existing toolset
- Requires developer intervention to instrument and/or code, and
- Adds to their “too much data, not enough insight” problem
ScienceLogic users gain visibility into application topology and performance within the context of business services and their overall IT estate. Instead of having our users mine traces and logs related to application performance, ScienceLogic’s intent is to integrate with key vendors in the APM and Observability market. SL1 will send requests to integrated systems for specific data. Those systems will return relevant data within the specified context. Ultimately, SL1 will analyze that data and automatically deliver insights on applications running on-premises and in the cloud to our users within the context of their existing ScienceLogic monitored IT estate. At the same time, by federating rather than collecting, storing, and analyzing all data from all applications (likely in overlap with existing systems), SL1 can reduce the effort and cost to deliver high quality business service and application performance.
Root-Cause Insights – In October, ScienceLogic announced the acquisition of Zebrium, a provider of root-cause analysis-enabling technology. Changing the paradigm from “show me more data” to “tell me what’s wrong,” Zebrium’s technology ingest logs and applies machine learning to observe patterns of log events and identify anomalies. It automatically analyzes relevant logs to determine unusual behavior and its root cause and then generates a root cause report delivering a word cloud of causes and impacts as well as a plain language summary of the anomalous behavior and its root cause.
Rather than forcing users to painstakingly mine numerous logs in a search for problems and their root cause, Zebrium’s capabilities “automate the observer,” helping our customers avoid “death by data,” to better understand their complex cloud-native modern applications and business services. And in the face of outages, performance degradations, and anomalous behavior, Zebrium helps to gain insight quickly and efficiently into the root cause with minimal-to-no human involvement.
A Roadmap for the Future of IT Operations
While targeted insights and root cause insights evolve and supplement our existing focus on the See and Contextualize elements of AIOps, Act is foundational to ScienceLogic’s “Autonomic IT” vision for AIOps. The end state of self-driving automation is enabled by recommended actions derived from real-time insights and curated by past results.
By connecting the IT ecosystem, SL1 leverages the data and insights to increase efficiencies across ITOps, DevOps, SecOps, and DevSecOps. With cloud-native and microservices-based applications now treated as first-class citizens of the IT estate, users of SL1 will be able to leverage these machine-driven capabilities across all elements of their business services.
The consensus among industry analysts, investment analysts, and those of us who live in this world is that the future of the enterprise is cloud native. Knowing what the future has in store, and what challenges that future holds, means being better prepared to meet those challenges. ScienceLogic understands that future, and what it takes to manage the complexities that come with a deluge of data associated with cloud-native services and technologies.
SL1 is already the AIOps platform best suited to meet those challenges, and our vision means we have a roadmap that ensures an investment in ScienceLogic is one that will support your organization’s business and operational goals for the long-term.
Learn more about the ScienceLogic SL1 platform»
1https://www.gartner.com/en/newsroom/press-releases/2021-10-18-gartner-identifies-the-top-strategic-technology-trends-for-2022






