By Richard Chart, Co-Founder & Chief Scientist at ScienceLogic
At the heart of every SL1 deployment is a relational database. At ScienceLogic, we have used MySQL and its derivatives such as MariaDB since designing our very first monitoring solution back in 2003. This database has served our customers well and has proven remarkably scalable. But with the move towards SaaS as the primary delivery model for ScienceLogic, it was time to look at alternatives.
Database Requirements
We chose Amazon Web Services (AWS) early-on as the primary provider for our SaaS cloud infrastructure, and within the AWS universe there is a wide array of choices for relational databases.
A key requirement of our database choice was compatibility with the MySQL client to minimize application-level difference with our customer-premises-based product. Beyond that, many of the operational requirements our customers have for on-premises deployment apply equally in SaaS:
An infrastructure footprint that matches the size and functionality of the deployment
Operational complexity that is kept to a minimum through smart packaging and automation
A platform that scales up or down to meet the needs of the organization (or organizations, in the case of multi-tenancy)
Performance and responsiveness that matches the consumer expectation – whether via the GUI or API
Resilience in the face of component failure, with built-in redundancy at every level
A further consideration relates to the various types of data we need to store in SL1 databases. Being an all-in-one AIOps platform, SL1 must ingest and store data relating to collection , system configuration, time-series performance data, logs and traces as well as adding context using discovered relationships between all these components. Each of these data types have very different structures and usage profiles, for which we had to consider the most efficient way to process and store.
Not all of these data elements are perfectly suited to storage in a relational database, so the full SL1 data lake uses other data stores in addition to SQL. However, having the flexibility to use a single relational store, where size and required features allow, reduces operational complexity significantly when single tenancy is required.
We could of course have supported these requirements with our own engineering effort: building out resilient database services on top of AWS EC2, but that would bypass some of the key benefits of operating in a public cloud. Why build out replication, failover, and backup infrastructure when there are pre-built services available to do all those things?
There are multiple MySQL compatible service offerings available within AWS, both from Amazon and from third-party suppliers. One of the most interesting of these is the AWS RDS Aurora service, introduced by Amazon in 2014. Aurora offers strong MySQL compliance coupled with a highly performant and resilient backend, engineered to take full advantage of the AWS availability zone architecture.
Why We Chose AWS Aurora
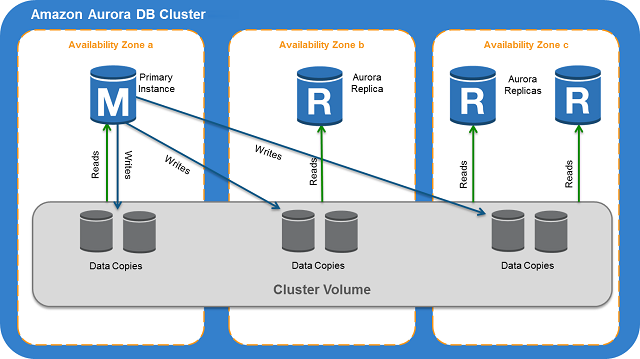
A database running in Aurora actually has at least six replicas deployed: two in each of three availability zones across an AWS region. Failover from the primary write replica to a secondary replica in another AZ occurs in seconds, while scalability is assured with automatic store expansion and simple instance upgrade.
We settled on AWS Aurora to meet our SaaS relational database needs. With its strong MySQL compatibility, we needed to make very few application changes to accommodate use of Aurora. Where there are differences, there are generally alternatives which simply integrate with the AWS infrastructure (checkout SELECT INTO OUTFILE S3 for an example of this).
The decision to rely on Aurora has been justified by the ability to support the full range of global customer requirements with very high-service availability.
AWS claims a five-fold performance benefit for Aurora over MySQL on certain benchmarks: we have not seen that level of jump with SL1 workloads, but our customers using the service have seen excellent responsiveness and they, and we are very satisfied with the service we have been able to offer underpinned by this technology.