As described in part one of this blog series, a key missing piece of observability is the ability to easily understand what is wrong inside your software system. And machine learning-driven automated root cause analysis is the missing link that addresses this gap because humans are struggling to keep up with the rapid growth in IT scale, complexity, and speed.
So how does one automate this task?
The Classic Process
For machine learning to solve this problem, we must first understand how it would be approached by the most experienced and skilled troubleshooter. As pointed out earlier, they would scan the key golden signals to understand when the problem occurred, and optionally traces (application, microservices, and sometimes infrastructure) to narrow down where.
Classically this means using metrics (samples of time series data) to know when the problem happened. Then (if available) use traces to narrow down which parts of the system were affected (the “where”). And finally, look at log events to understand “why” the problem happened.

Simpler problems might be root caused just from the first two steps. For instance, a gradual saturation of CPU, memory, or disk does not need much troubleshooting – it just indicates resource exhaustion. But a sudden spike or sharp change in one of your golden signals doesn’t tell you the root cause. Which is why you need to look at log events.
Why Logs
Logs have three properties that make them extremely versatile and valuable for troubleshooting:
- Ubiquity: pretty much any kind of software is already “instrumented” with log messages, to help the original developer debug. You don’t have to add code to create custom events or traces.
- Specificity: golden signals as symptoms can be far removed from the root cause, and do not necessarily have a simple relationship with root causes. For example, a spike in latency could be caused by any number (potentially thousands) of factors. In contrast, when you see a specific log event, you pretty much know which part of the software generated it, making logs very reliable indicators for root cause analysis.
- Semantic Richness: developers typically annotate their log events with short phrases or keywords that are human-readable and mean something. Although this makes logs harder and messier to analyze, once you know the key log events you can take advantage of this property to extract the keywords that even an unskilled operator could understand. You can also leverage this semantic richness to correlate a set of logs with accumulated knowledge in a ticketing or bug database, or even the public internet.
What would a skilled human do?
If you ask an experienced engineer how they go about troubleshooting, they will describe roughly the following process:
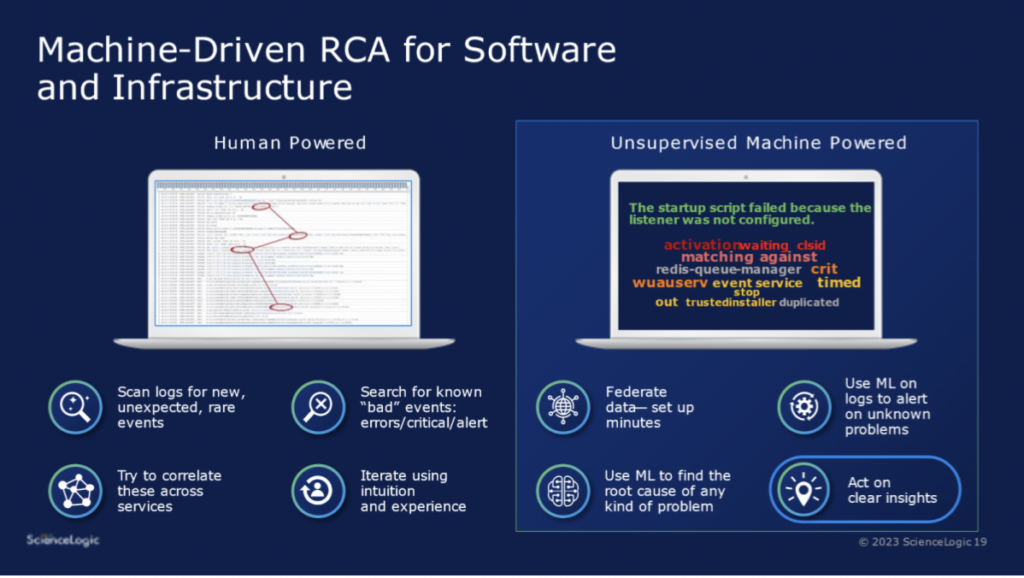
1.) You start by looking at log events (typically millions) within the scope of the time frame and affected services. Skilled engineers will first look for unusual spikes in “bad events” – errors, warnings, alerts, etc. But these are likely to be symptoms.
2.) Then the engineer starts scanning logs backward, looking first for known indicators of problems and then looking for anything “unusual” or “weird”. Unusual events aren’t typically errors – they might indicate a config change, a new deployment, a user action, or something equally benign.
3.) Based on intuition, the skilled engineer will then infer the connections between these unusual events and the downstream errors (which are quite likely to reside in different log streams).
4.) They may also search the public domain (e.g. StackOverflow) for mentions of the suspect events, to increase confidence in their hypothesis.
Replace Brute Force Effort with Machine Learning
The bad news is that this process can’t be automated by simple rules, pattern matches, or scripts.
The good news is that a well-designed and suitably trained machine learning model can be trained to emulate each step taken by the human, generate results that are extremely accurate – and do it all much faster. For instance, once trained, a good machine learning model can easily pick up spikes in errors. It can also identify outliers very accurately. In years past this domain has seen a lot of disappointment due to poor accuracy and noisy results. The good news is that advancements in machine learning have finally made it possible to accurately detect outliers, and once again machine learning is much, much faster than humans at this task. It’s not hard to imagine how the final steps are also a great application of machine learning – identifying correlations between rare root cause indicators and their obvious symptoms (because they are errors). And then comparing these root cause indicators against accumulated knowledge bases – for example, the public internet using techniques such as GPT-3.
Check out this video for a deeper dive into the technology.






