As described in parts one and two of this blog series, a key missing piece of observability is the ability to easily understand what is wrong inside your software system. And machine learning-driven automated root cause analysis is the missing link that addresses this gap because humans are struggling to keep up with the rapid growth in IT scale, complexity, and speed
This blog describes how ScienceLogic is going even further to help the human observer.
The Vision
Years ago, a software entrepreneur coined the term “Cluster Immune System” to describe a comprehensive wish-list of all the capabilities he wished his monitoring and management tools offered, to help his team run their software estate efficiently. Recently Gartner has used the term “Digital Immune System” to describe a set of “practices and technologies for software design, development, operations and analytics to mitigate business risks”. In slightly different ways, both describe a dream system that protects your applications and business services from bad outcomes, while at the same time helping your team work efficiently. This ideal future state is supposed to work by automatically detecting new problems, understanding the reasons, and automatically recovering quickly from the problem.
The reason for this desire is simple—we live in a world where there is growing pressure to move faster to support business goals, ever increasing complexity, and at the same time a shortage of skilled resources to help us achieve of all of this. This is where intelligent, AI-driven automation can help. AI-driven automation can help us see problems quickly, understand their business impact, figure out the root cause, and take corrective actions automatically.
This is the vision ScienceLogic is working towards, and the end state we seek to enable for our customers.
The Building Blocks
Stage one of this fully automated workflow starts with collecting the key telemetry from your systems, so you have visibility into every component that could impact your key services. ScienceLogic has the broadest set of data collection capabilities today – ranging from cloud-native microservices to containers and VMs and extending all the way to physical entities such as network devices and laptops. This is what allows you to understand what is going on in your environment, collecting metrics, logs to give you a comprehensive view of your environment.
Stage two of this automated observability pipeline allows you to contextualize. In other words, it helps you understand how the lowest level building blocks are contributing to high level abstractions such as business services. It automatically catches unusual events (outliers, anomalies) and identifies correlations between them. Crucially, it also automates root cause analysis of any problems within the environment, so you understand what is going in within the system. ScienceLogic can do this at least as accurately as a human observer, but much, much faster that a human, and in a way that scales extremely efficiently.
The outcome of stage two is a root cause report, with a unique fingerprint, and an automatic scan of this fingerprint against existing knowledge repositories of known problems.
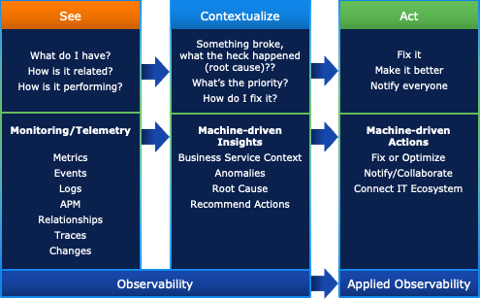
Stage three allows you to complete the journey with actions. Once you have identified the root cause of a problem, and fingerprinted it reliably, you should be able to automate corrective actions in many, if not most cases. This means it should be easy to link a unique root cause fingerprint to a corresponding automated remediation action (which might be carried out by runbook automations or automated workflows). And it should be quick and easy for even a relatively unskilled operator to build new automations for new problems, as quickly as they are uncovered, and root caused by the observability pipeline.
Again, ScienceLogic arguably offers the richest automation capabilities in the market today, with a library of existing automation best practices, and a low-code, no-code workflow automation framework (SL1 PowerFlow) to empower any operator to quickly build more.
Putting It all Together
While there is much to come in our roadmap, you can see why ScienceLogic is the company best positioned to help software, IT, and operations teams achieve the nirvana end state of a “self-healing immune system”.
This is a system that automates the observer—giving you visibility into your environment, but also the internal workings of your software. So, when things go wrong it doesn’t just show you symptoms—it tells you how and which business services are impacted. And with high accuracy it also shows you the root cause of the problem. And it doesn’t just help you automate observability. It also helps you automate the corrective actions that result from the observability results.
To learn more, request a free trial>>






