




Intelligent Automation, Simplified
Skylar Automation brings observability and automation together to keep IT moving. From simple tasks to complex multi-vendor workflows, it adapts to your environment with supervised and unsupervised execution. Bidirectional synchronization, optimized data handling, and scalable architecture provide efficiency and transparency across the entire stack.
A built-in MCP server extends these capabilities to MCP-compatible AI agents, enabling them to query current operational context and initiate permission-controlled workflows through installed SyncPacks.
See it in action with the Skylar Automation Builder
Boost IT productivity with easy-to-build workflows.
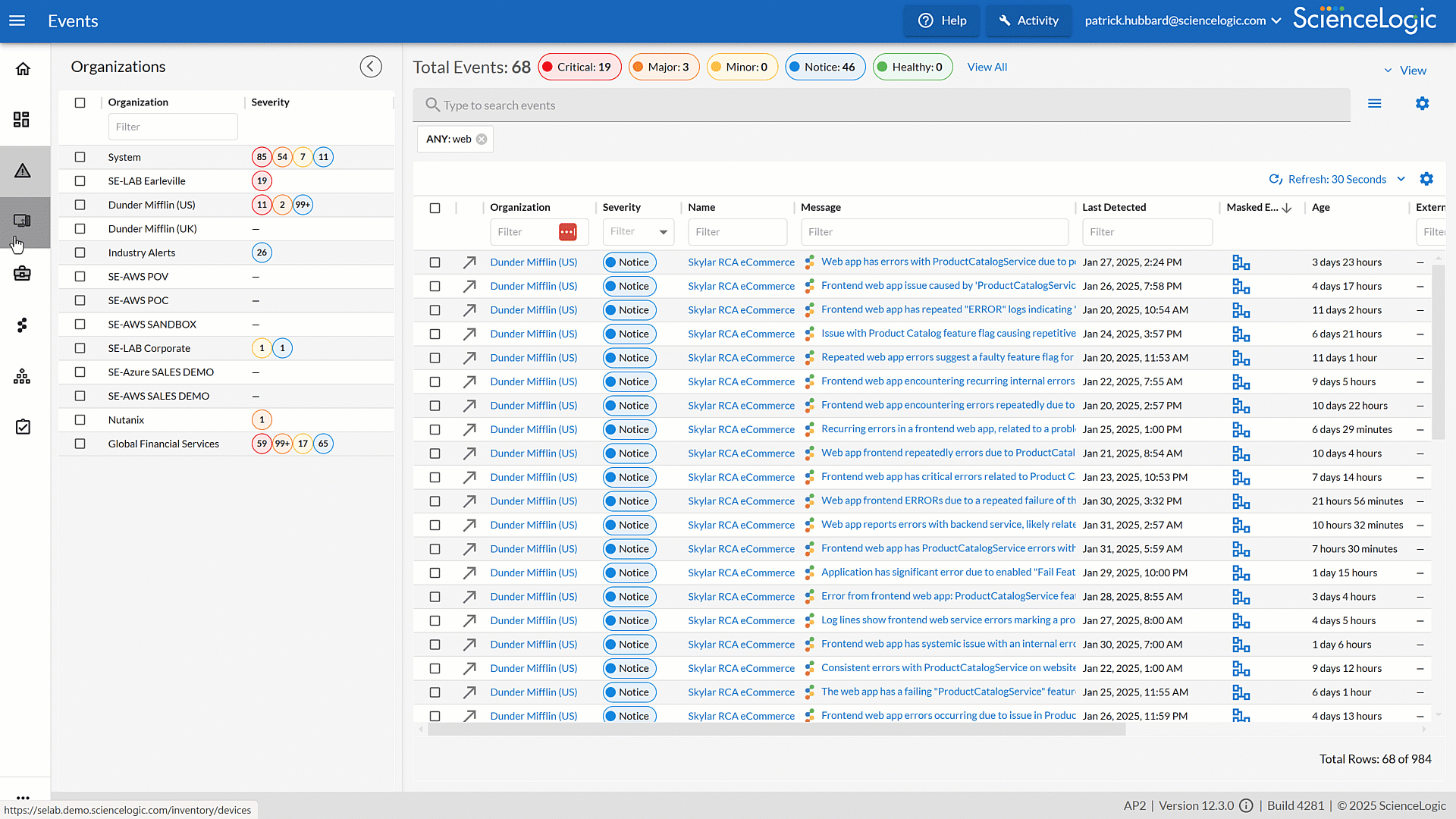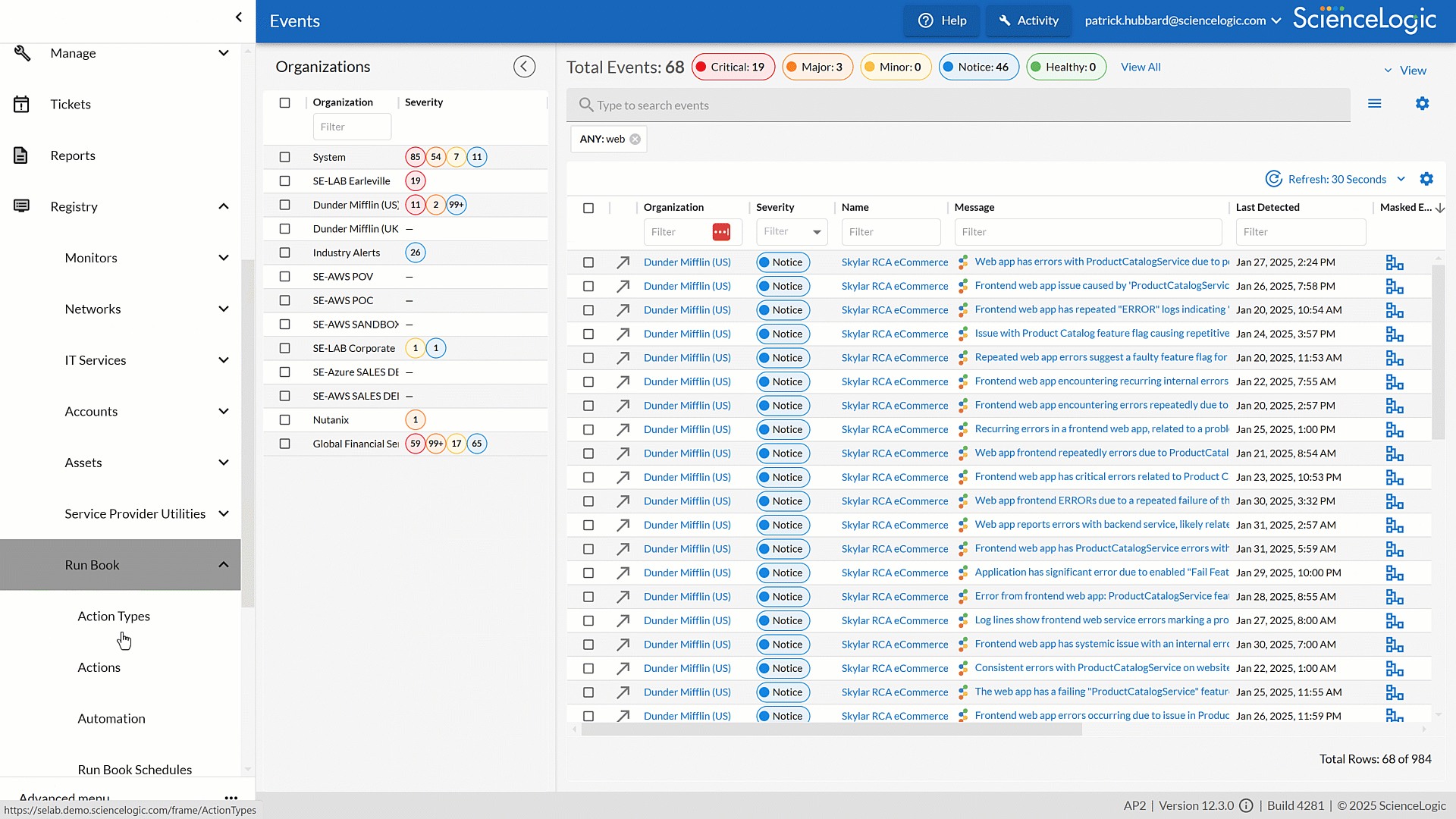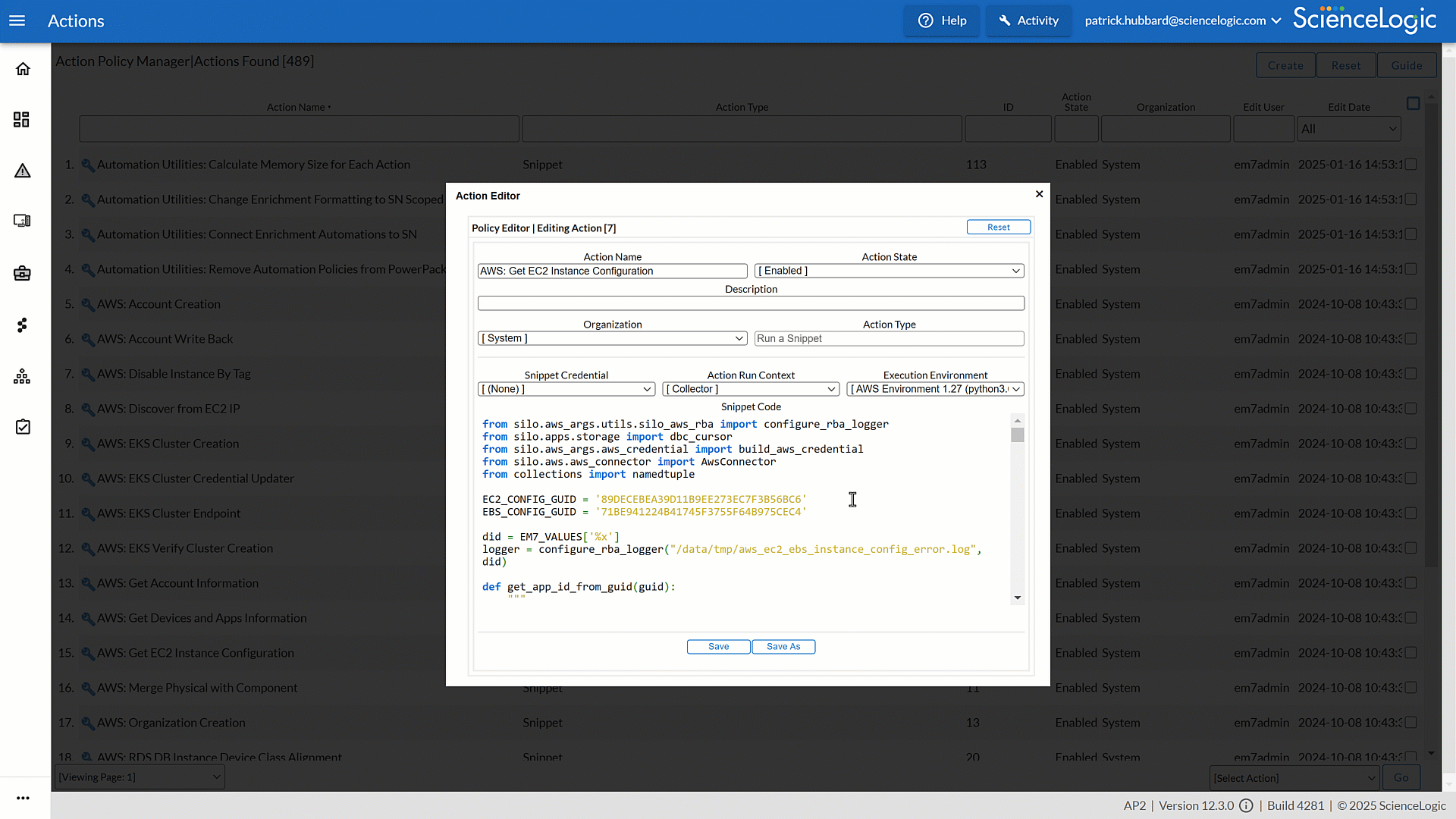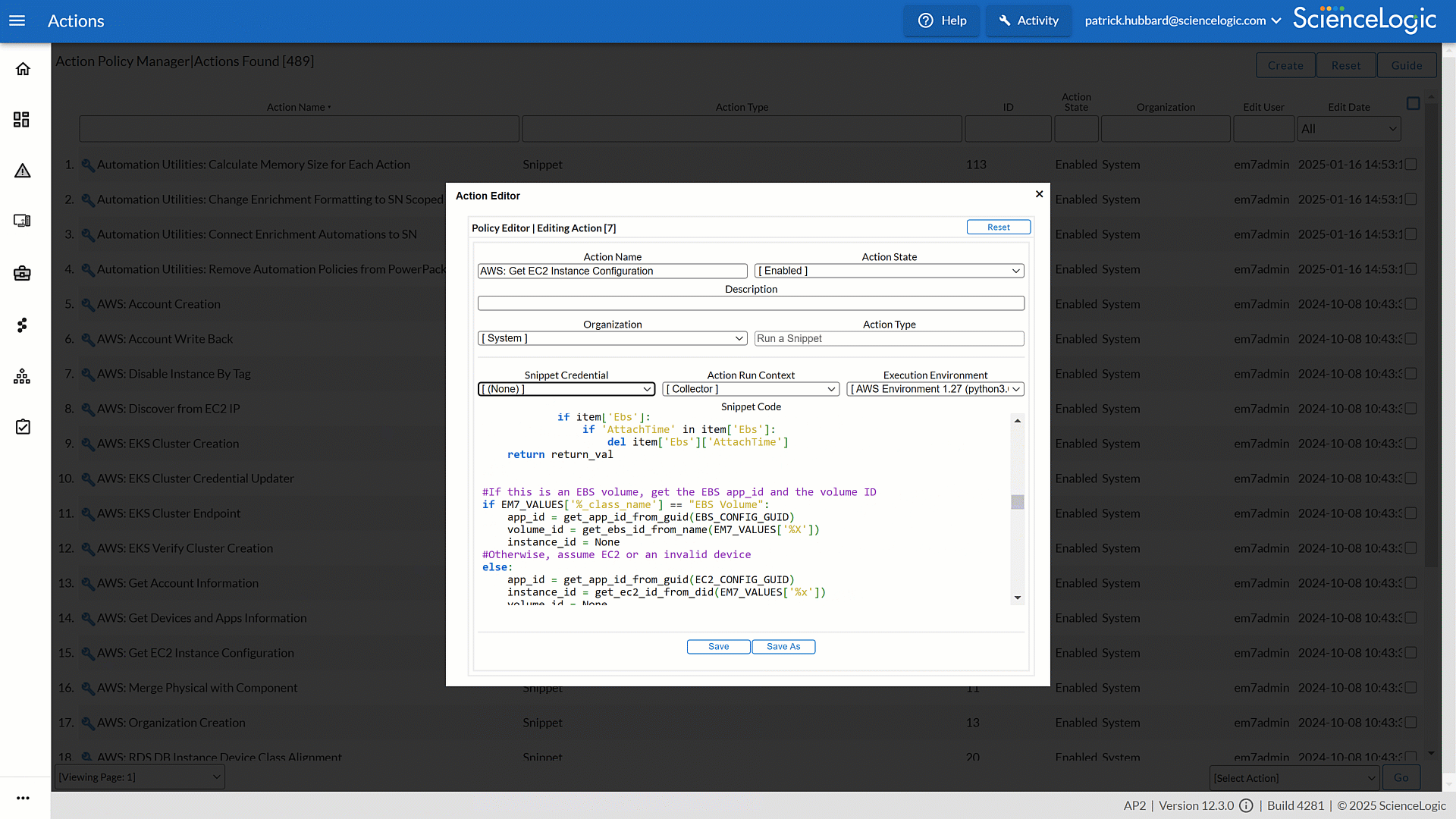
Streamline Operations with Built-in Run Book Automations
Skylar One’s (formerly SL1) Run Book Automations (RBA) simplify IT management by automating repetitive processes and ensuring faster, more consistent responses. With built-in intelligence, RBAs cut down on manual effort, reduce errors, and keep services running smoothly.
- Simplify your operations with 350+ automation and automated workflows to reduce operational toil, lower MTTR and ensure repeatable, consistent execution across IT.
- By automating routine processes, you minimize manual errors and free staff to focus on higher value, strategic initiatives.
- Through dynamic automation capabilities, incident trigger diagnostics and remediation the moment they occur, reducing downtime and customer impact.
Maximize Efficiency with Built-In Integrations
Skylar Automation’s built-in integrations connect your tools and data without the headaches of custom coding. SyncPacks translate and format data between third-party apps, ensuring systems communicate seamlessly and reliably.
- Enhance connectivity with SyncPacks that standardize and translate data across applications.
- Simplify SaaS integrations with providers like ServiceNow for CMDB and ITSM, for faster, cleaner data flow.
- Maintain transparency with scheduled that shows what data was synced and when.
Enhance Productivity by Creating Custom Automations
With Skylar Automation Builder, you can create workflows tailored to your environment. Its intuitive design puts you in control, making it easy to adapt automation to your unique process.
- Design custom integrations with a drag-and-drop interface built for quick setup and data management.
- Easily map and schedule tasks without heavy coding, enabling teams to build and refine workloads faster.
- Use replay functionality to regenerate scenarios with the same payload, speeding troubleshooting and application development.
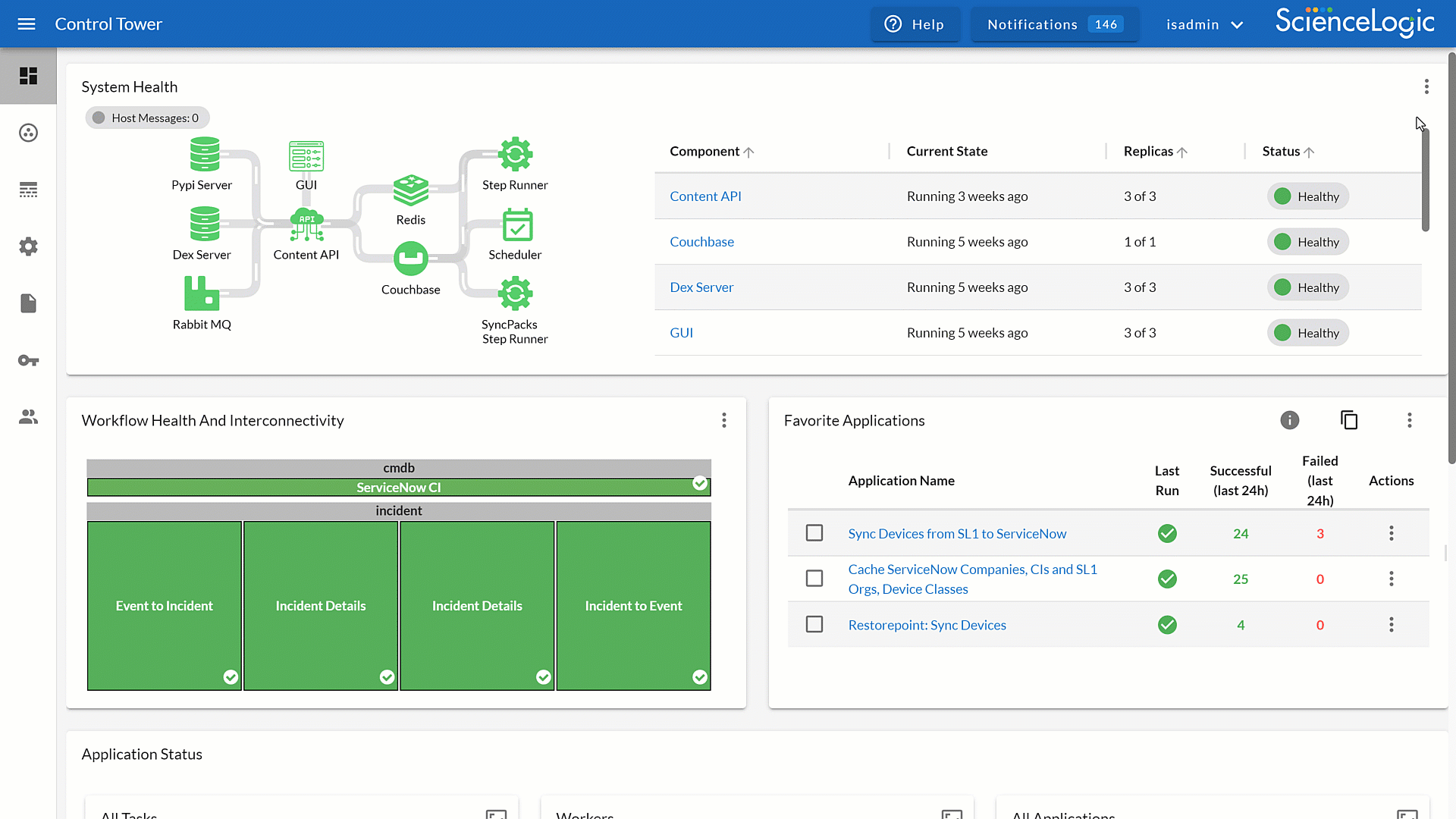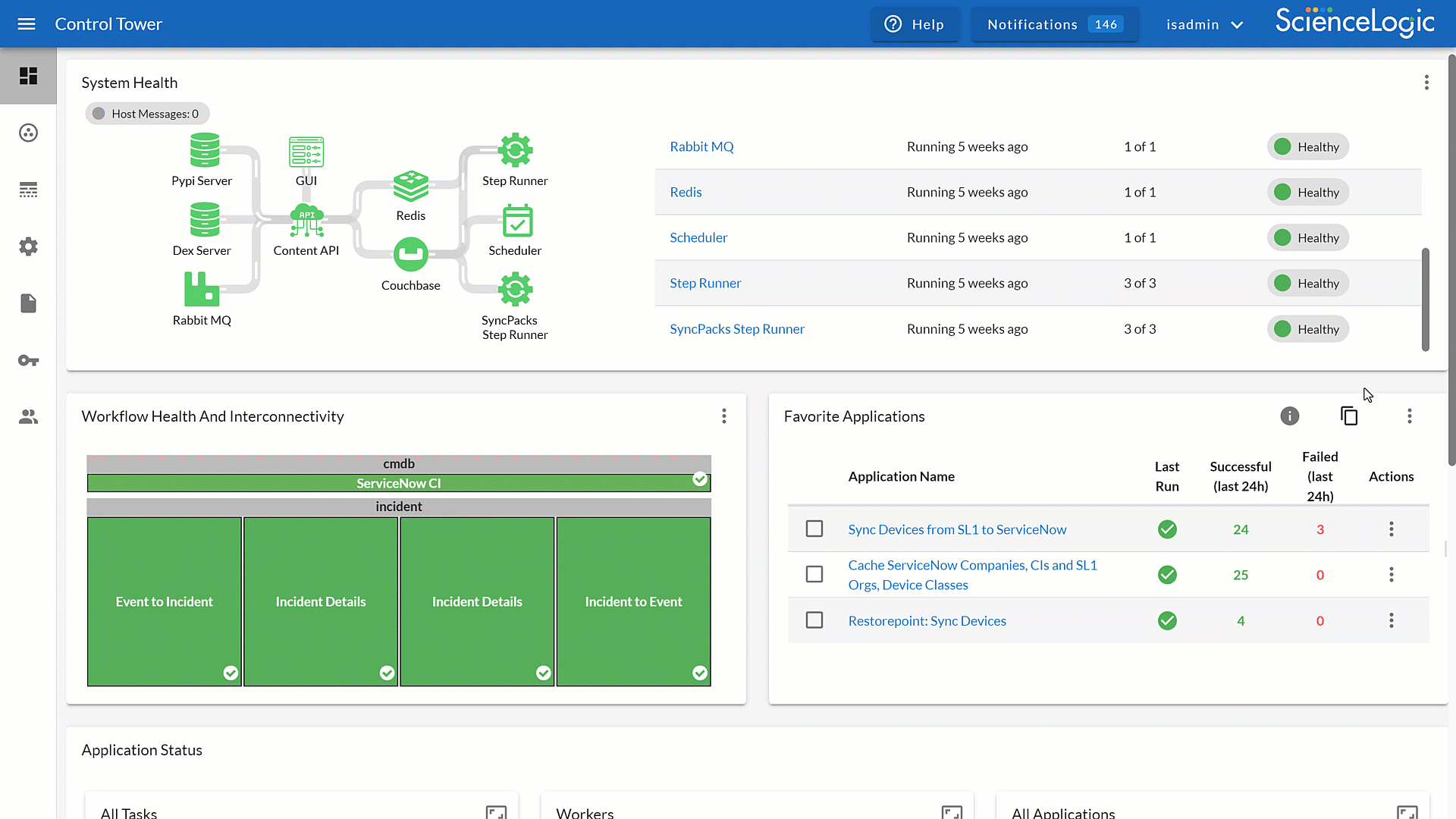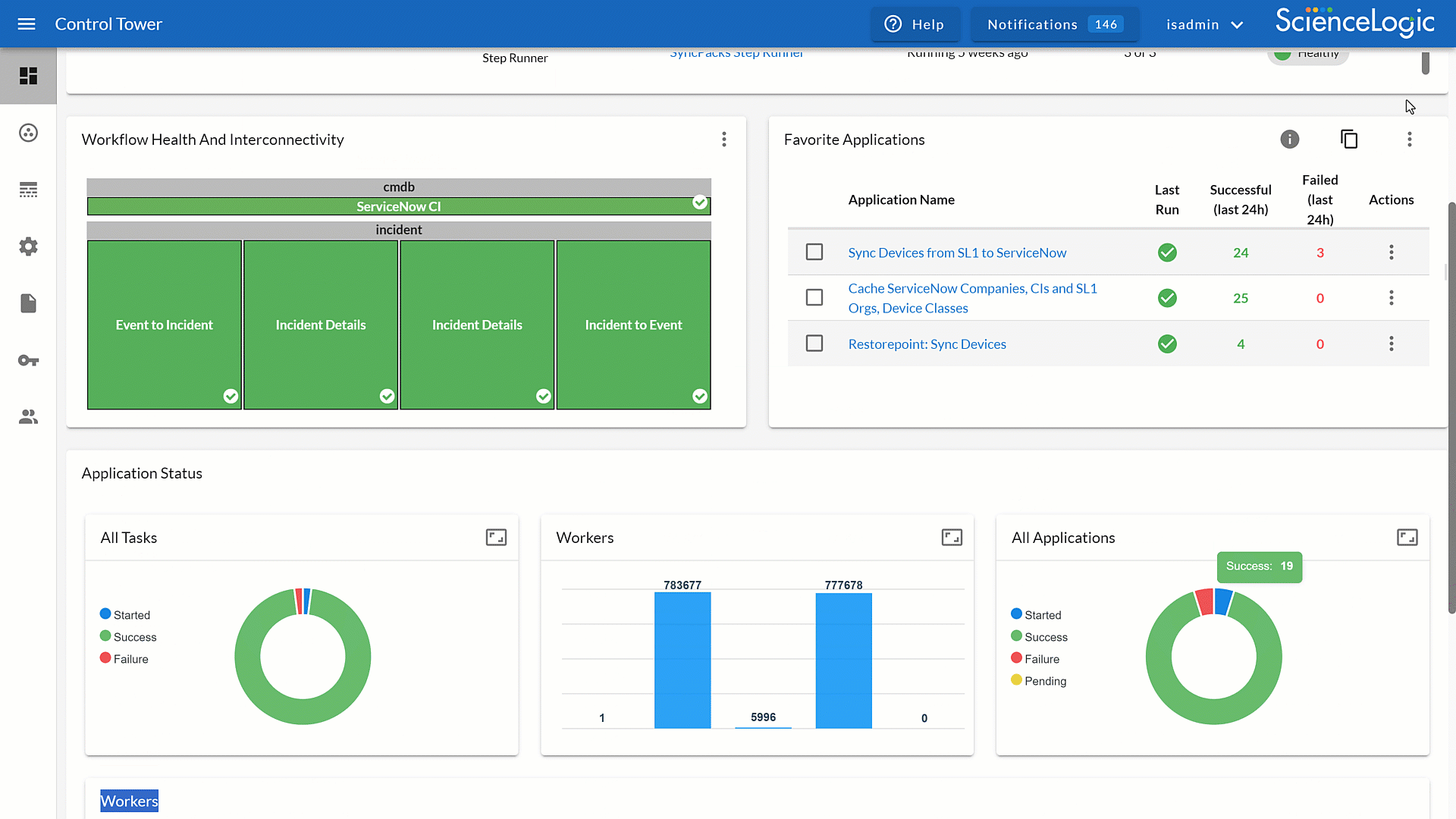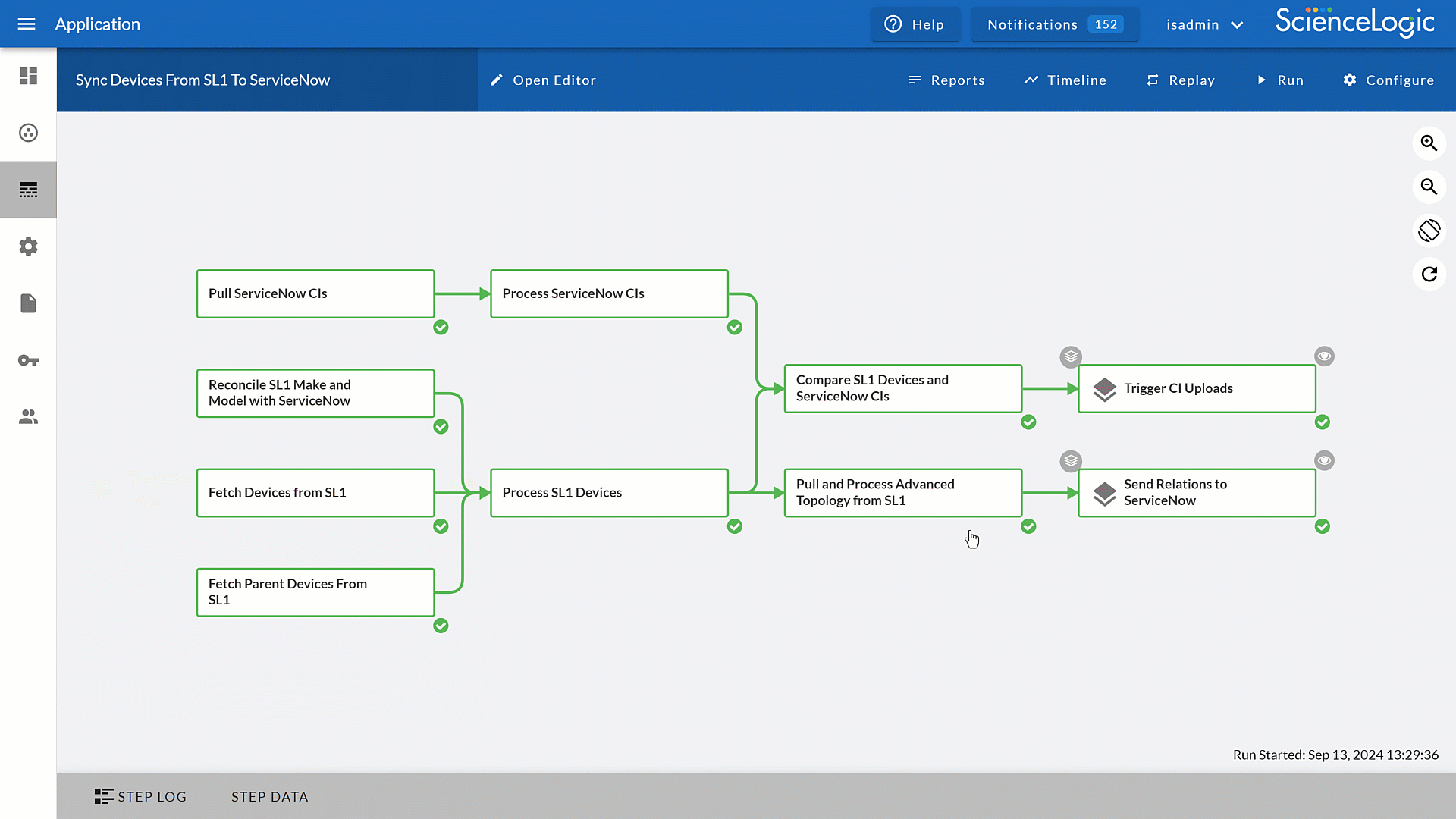
Optimize Workflow Management with Control Tower
Control Tower, part of Skylar Automation, gives you centralized observability across all your automations. By tracking workflows in real-time, you can ensure efficiency, consistency, and reliability through your environment.
- Gain real-time observability to spot anomalies early and resolve them before they escalate.
- Measure automation usage and performance to confirm workflows deliver maximum business value.
- Maintain reliable operations across single or distributed environments with consistent, scalable, oversight.
Pioneering AI-Based IT Operations Management for Unparalleled Resilient Outcomes
Flexible and Scalable
Automate IT at scale to stay competitive, agile, and responsive in a rapidly changing digital landscape.
Open and Extensible
Connect MCP-compatible AI agents to ScienceLogic operational data and workflows through a built-in MCP server and reusable SyncPacks.
Human-Centric AI
Stay in control with a proven, human-assisted AI platform trusted for critical IT operations decisions.
Ready to Get Started?
See how today's technology leaders are using ScienceLogic to transform IT operations, centralize configuration management, and resolve issues 10x faster. Fill out the form to request a demo.