We often get asked how Zebrium ZELK Stack machine learning (ML) compares to native ML for Elasticsearch. The easiest way to answer this is to see the two technologies side by side. This short (3-minute) video demonstrates what each solution is able to uncover from the exact same log data. No manual training, rules, or special configuration were used for either ZELK or ELK.
If you don’t have time to watch the video, we simulated a problem by shutting down PostgreSQL in our production Atlassian environment which caused the Jira application to fail. The logs from this were sent to both ZELK and ELK.
These two pictures show the end result:
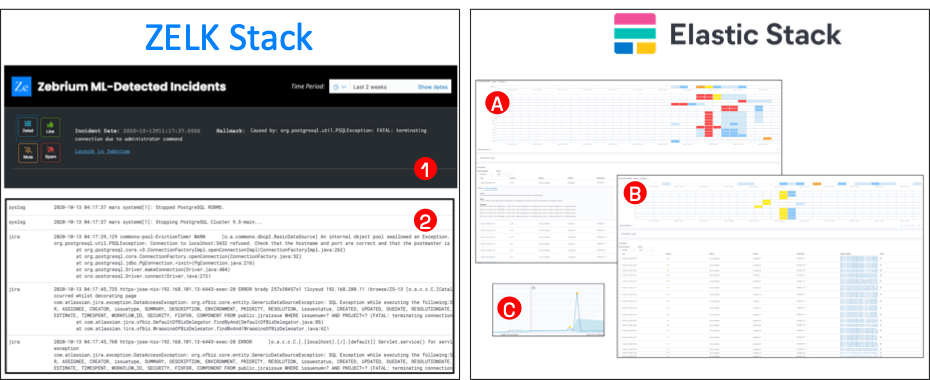
ZELK Stack (LHS):
- (1) The ZELK incident dashboard shows a single incident: “SQL exception due to administrator command”.
- (2) Clicking the incident details button shows the root cause (SQL stopped) and the symptoms (Jira exception unable to communicate with SQL).
- Within seconds of looking, it was clear that ZELK was able to not only catch the problem but also show its root cause.
Elastic Stack (RHS):
- I configured three different machine learning anomaly detection jobs to try and find the problem.
- (A) and (B) use Elastic machine learning categorization to look for event categories with abnormal counts within 15-minute time buckets.
- (A) shows event categories with anomalous counts – which didn’t yield anything useful.
- (B) shows rare event categories and, at the time the incident occurred, it found almost 300 examples of rare categories. I manually looked at each one and managed to find the “SQL stopped” event (it was ML category #102).
- (C) shows anomalies in event rates. One of the smaller spikes coincides with the time of the problem, but it would be difficult to pinpoint the problem just from this.
Summary: Incident Detection vs Anomaly Detection
Zebrium’s goal is to use machine learning to catch incidents and show root cause. It does this by looking for hotspots of abnormally correlated anomalous patterns across logs and metrics. It has been tested with hundreds of production software stacks and typically achieves accuracy with few false positives within approximately 24 hours – without requiring any manual configuration or training. Best of all, with ZELK Stack, you can do all of this right inside the Elastic Stack.
Elastic ML anomaly detection (part of X-Pack in the Elastic platinum pricing tier) is able to categorize events and then find anomalous event counts within user-defined time buckets. It can also find anomalous event ingest rates. A user can build and tune machine learning jobs to visualize these anomalies. However, as the example above shows, the dashboards often require significant human inspection and analysis in order to find useful information.
Please try this for yourself using your own data. You can find out more and sign up for a free trial here.






