

See why our AI Platform fuels innovation for top-tier organizations.

Experience the platform and use cases first-hand.
Observe. Advise. Automate.

Feel the power of AI-Driven Observability with a 14-day test drive.
From automating workflows to reducing MTTR, there's a solution for your use case.

Gartner evaluates observability vendors.
Catalyze and automate essential operations throughout the organization with these insights.

See why ScienceLogic has been named a Leader, with the highest score in the Strategy category.
We’re on a mission to make your IT team’s lives easier and your customers happier.

Join us for a practical mid-year review of the trends reshaping IT operations.
Why is application dependency mapping so important? And how do you maximize its value to in your organization? We’re here to provide you the answers.
If you ever find yourself navigating the back roads of Maine and stop to ask for directions, don’t be surprised if the old farmer in his green cap and Dickies slowly drawls, after giving it considerable thought, “You cahn’t get theyah from heah.”

The idea is that the topology in that corner of the world presents a host of problems for locomoting. Mountains and gullies, rivers and lakes, lack of signage, an abundance of signage, dirt roads, landmarks and lexicon known only by locals, seasonal variations, and a lack of connectivity for the GPS-dependent all conspire to make navigation difficult under the best of circumstances. It sounds a lot like typical network topology, come to think of it. But while a meandering trip over Downeast byways might be an appealing way to spend an afternoon, it’s no way to manage your IT infrastructure.
In fact, a 2016 Forrester report entitled IT Efficiency Begins With Effective Discovery and Dependency Mapping found that enterprises engaged in IT projects like virtualization and server consolidation were hindered because they did not have a complete view of dependencies (56%), did not know what resources were required by the various applications (36%), and lacked a complete view of all the applications in use by the enterprise (31%). That is a lot of blind spots. And it is why comprehensive enterprise discovery, contextual topology, trusted data, and application dependency mapping are critical to IT operations. They are complementary components of managing today’s IT ecosystem.
You can’t manage what you don’t know and, with the complexity and ephemerality inherent in today’s networks, that information can change from moment to moment. In a 2018 white paper, Next-Generation ITAM Building for Tomorrow’s Use Cases Today, Enterprise Management Associates (EMA) identified the top ten challenges for efficient IT operations. All ten were either directly or indirectly associated with incomplete or inaccurate data, including:
Application dependency mapping is pretty much what the name says it is: a process of identifying all the elements in an ecosystem and understanding how they work together. It’s connecting a lot of dots to give IT managers a clear picture of their environmental health and overall application performance. Application dependency mapping is important for IT operations management because when things go wrong, it is critical that you quickly identify the points of failure and find the fastest path to recovery.
Every application—from a complex e-commerce application to something as common as email—has a lot of moving parts. If performance is slow, application dependency mapping lets you know where to look to understand where the bottleneck is, what resources might be overtaxed, and how to resolve the problem. If an application isn’t working, the application of a reliable dependency mapping tool is the key to identifying where there might be a disconnection or if something needs to be replaced.
It stands to reason then that if your map is incomplete or out of date, you may not be able to find the problem and you won’t be able to get there from here. There might be a workload you don’t know about—or that you thought had been retired—sapping compute power from an application you rely on and if you can’t find the source of the problem you will find yourself on a wild goose chase. But with acomprehensive discovery of the entire IT infrastructure, contextual network topology, and trusted data behind your application dependency mapping, you can get there from here. The EMA report found that enterprises that were the most successful at IT management were “likely to have an application discovery and dependency mapping (ADDM) capability deployed.”
While the concept of application dependency mapping is self-evident, the implementation of mapping tools is a little more complicated. There are different approaches and levels that can produce different results. There are also misconceptions about application dependency mapping that can hinder decision-making and achieving optimal results from your investment in application mapping.
While the concept of application dependency mapping is self-evident, the implementation of application mapping tools is a little more complicated. There are different approaches and levels that can produce different results when application monitoring. Depending on which approach you use for automated discovery and mapping, you may be at risk of not seeing your IT ecosystem in its entirety. That’s because some older systems are engineered to operate in a specific environment or for specific management platforms.
Within the realm of agent and agentless discovery, there are three well-established techniques for accomplishing application dependency mapping, all of which have their pros and cons:
PROS
CONS
PROS (NetFlow & Packet)
CONS (NetFlow)
CONS (Packet)
Agents can provide a real-time monitor of both the incoming and outgoing traffic to find and understand every component and immediately recognize changes to status as topology changes.
PROS
CONS
There’s also a fourth source of application dependency mapping emerging, which leverages orchestration platforms themselves. Platforms like Kubernetes, Cisco CloudCenter, or ACI deploy and maintain all of the underlying application components. As a result, the orchestration knows at any given point what individual components are part of a specific application. Since today’s IT ecosystem is highly ephemeral and you constantly need to monitor, measure, and manage what’s taking place within the environment, a hybrid strategy that combines the best of multiple practices is required. For example, the ScienceLogic SL1 Platform can combine application maps from AppDynamics and augment them with maps from our agents to provide a real-time, thorough view of what’s taking place within the IT ecosystem.
As you transition to Artificial Intelligence for IT operations (AIOps), application depending mapping is necessary, but it’s not enough. Why? Because application monitoring is insufficient on its own. Since there are so many different layers of technologies making up your IT infrastructure—from legacy to virtual machines to the cloud to microservices—that means that there are an increasingly complex set of dependencies between the app and the infrastructure. Changes to the application and underlying infrastructure occur so quickly that we are past the point where humans can figure out how these parts are related. We need a machine to do it for us. Today AIOps is not just a buzzword or something to think about doing next year. It’s become a necessity. You can’t afford not to. You cannot do AIOps workflows without a strong topology. The image above represents a typical, complex, multi-technology application, or business service. It shows the relationships between the application and the underlying layers of the infrastructure. What we do at ScienceLogic is:
This way, if/when something goes wrong anywhere in your infrastructure—which is often shared across multiple applications and business services—you can quickly identify the impact and isolate the root cause. Agents can monitor east and west between servers by watching application flows. But the north and south dependencies mostly come from other sources. ScienceLogic has patented PowerMap technology that discovers and maintains the north-south dependencies across all the layers of abstraction for private, public, and hybrid cloud environments. This true dependency map is the foundation of algorithms for event correlation, root-cause analysis, and behavioral prediction.
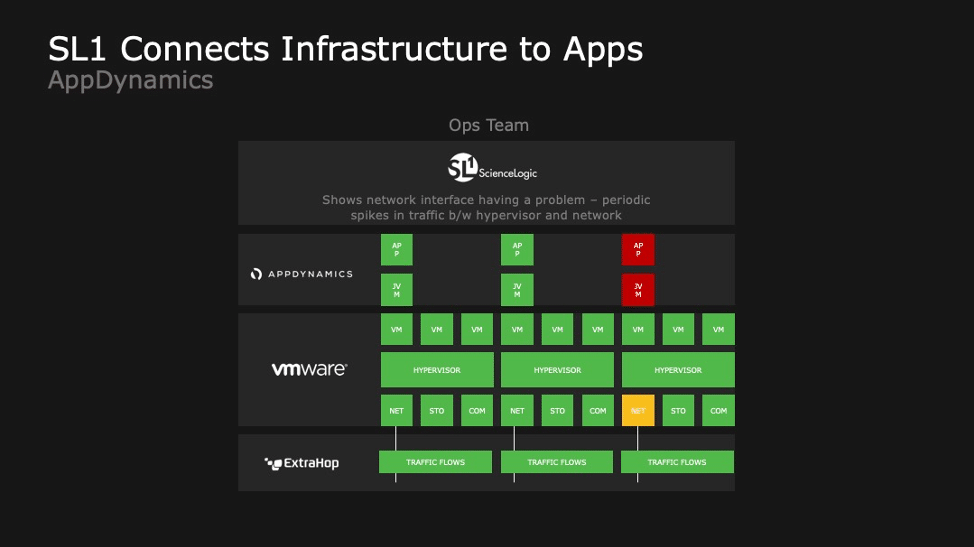
If you have an Application Performance Management (APM) tool like Dynatrace or AppDynamics, that’s fantastic. These tools give you application dependency mapping capabilities that provide you with a consistent view across your apps. But your infrastructure is not just made up of applications, is it? What if you have a LUN failure that is causing your app to underperform, like in the image above? An APM tool alone does not give you the root cause of why your app is underperforming. But the ScienceLogic SL1 platform does.
SL1 fuses events, performance, configuration, and relationship data from your APM tools like Dynatrace and AppDynamics with the rest of your infrastructure data, and it maps the APM tool’s hosts to the physical and virtual infrastructure—not just servers, but network, storage, and cloud as well. SL1 works with your APM tools to connect the dots by mapping the app relationships from the APM data with the app and infrastructure relationship data it collects natively across your entire IT environment. You get visibility across ALL your infrastructure and apps—not just the 10-20% of apps monitored by your APM tool.
Since applications are constantly evolving, you need the right application dependency mapping to provide you with the actionable insights necessary to accelerate your journey to AIOps. ScienceLogic is here to help you get there.