





Making Hybrid Infrastructure Monitoring Work For You
Introduction
What is Hybrid Cloud?
Hybrid cloud is a mixed computing environment where applications are run using a combination of computing, storage, and services in different environments—public clouds and private clouds, including on-premises data centers or “edge” locations. Enterprises are turning to hybrid IT models to blend their infrastructure on demand.
A good customer experience is one of the most important metrics of success for your enterprise. In order to deliver information, transactions, and interactions quickly and efficiently to your customers, you need to rely on a vast collection of interconnected technologies that work seamlessly together. But as transactions grow in complexity ─ and end users’ expectations increase exponentially ─ so does your IT infrastructure.
Hybrid cloud computing has disrupted IT
Hybrid cloud computing is about the ability to take advantage of on-demand cloud services. These services are designed to provide easy, affordable access to applications and resources, without the need for internal infrastructure or hardware. And whether those services are available internally, or purchased from a public cloud provider, they are made possible because of specialized, purpose-built, hyperconnected and secure infrastructure consisting of virtual machines, software defined networking, all backed by hypervisor-based automation and orchestration.
Just because IT is complex, doesn’t mean your monitoring should be. Each technology layer emits volumes of data that contain the information required to monitor, troubleshoot, and ultimately improve those experiences.
“…it is time to rethink your infrastructure monitoring.”
Hybrid Infrastructure Monitoring 101
Hybrid infrastructure is the collective grouping of interconnected technologies that includes servers, routers, and storage arrays in addition to software-defined anything running in your data centers and clouds. Infrastructure monitoring must provide visibility into all these technologies in order to actively diagnose performance, utilization, capacity, and bandwidth problems across the entire IT estate—before an outage hinders customer experience. Modern monitoring tools provide you with the ability to see what is happening across your organization’s infrastructure to help teams prevent outages—alerting your team to potential downtime, resource saturation, and business impact.
When you have comprehensive visibility into your entire enterprise, the potential problems that infrastructure monitoring tools identify can be solved quickly and effectively.
How do enterprises use hybrid clouds?
For each enterprise that transitions to hybrid cloud, various types of users deploy different operations to benefit the entire organization.
IT decision makers can:
- Automate the provisioning and management of on-premises and cloud resources
- Enable rapid virtual machine (VM) and container vending
- Accelerate the development process to bring new products to market faster than ever before
- Ensure cloud development self-service
- Turn a VM cluster into a private cloud
- Turn containers and bare metal into private clouds
- Connect to any provider
- Intelligently scale infrastructure
Chief information officers (CIOs) can improve productivity with hybrid cloud technologies that:
- Are capable of quickly turning up new services
- Can migrate IT thinking away from operations and toward applications
Developers can benefit from cloud environments that:
- Are fast-moving
- Include streamlined development project workspaces
- Have complete self-service provisioning, tools, and access to a catalog of curated tools, templates, and resources
Line of business executives can keep an eye on cost/productivity and use platforms and systems that help them to:
- Directly achieve their goals without constant IT intervention
- Enhance their individual service levels
- Improve the overall health of the business
Benefits of Hybrid Cloud
Although cloud services can drive cost savings, their main value lies in supporting a fast-moving digital business transformation. Every technology management organization runs under two agendas: the IT agenda and the business transformation agenda. Typically, the IT agenda has been focused on saving money. However, digital business transformation agendas are focused on investments to make money.
The primary benefit of a hybrid cloud is agility. The need to adapt and change direction quickly is a core principle of a digital business. Your enterprise might want (or need) to combine public clouds, private clouds, and on-premises resources to gain the agility it needs for a competitive advantage.
Additional capabilities of a hybrid cloud include:
- Connect multiple computers through a network;
- Consolidate IT resources into a single pool;
- Scale out and quickly supply new resources;
- Be able to move workloads between environments;
- Incorporate a single, unified management tool; and
- Orchestrate processes with the help of automation.
Challenges in Today’s Complex IT Environments
1.) Infrastructure Monitoring in Today’s Hybrid IT Ecosystems
Modern IT is an extraordinarily complex myriad of interconnected technologies, each of which has the potential to run into performance issues or fail outright. And with more transient components (including serverless and microservices) being introduced continuously, more frequent and severe opportunities for outages arise.
2.) Delivering Visibility Across Data Center and Cloud
Many enterprises have moved to, or are considering, using the cloud to increase business agility and shift their operational cost from fixed to variable.

A Roadmap to Modern Infrastructure Monitoring
Separate monitoring tools for each layer of the IT infrastructure are a fundamental issue when it comes to understanding the health of the whole system and solving any problems that arise within it. A single platform with a unified experience that provides ITOps with access to all the information across domains opens up opportunities for cross-functional investigation and holistic end-to-end infrastructure monitoring. It removes blind spots from the system and, as a result, reduces mean time to resolution (MTTR) because teams can more quickly identify the problem, fix it, and move forward.
The answer to the problem is to have a single tool that ingests all of the data and provides onboard correlation and alerting functionality.
Step 1: Map Relationships Between the Infrastructure and Applications
Most of today’s enterprises have significant gaps and overlaps in visibility across the datacenter, cloud, hybrid cloud, and containers, resulting in increased operational costs and the uncertainty of conflicting sources of truth. You need to see across your entire IT ecosystem (what you have, what it is, and how it works together), and understand how each component is related to each other (topology).
Organizations benefit from monitoring solutions that go beyond the infrastructure and show relationships through app-to-infrastructure mapping so that you can understand how the infrastructure and apps work together for a particular technology. Every application—from a complex financial services application to something as common as email— has a lot of moving parts. For example, if performance is slow, dependency mapping lets you know where to look to understand where the bottleneck is, what resources might be overtaxed, and how to resolve the problem.
Once you have these insights you know your next course of action should be to move workloads around or add capacity to handle spikes in usage.
Also, applications today are not running on dedicated infrastructure. They are relying on different components that are spread out throughout your entire IT ecosystem and can be shared with other applications. This makes having visibility across all your applications so important because it enables you to pull resources from other components to support others.
An example of this would be an eCommerce website needing to allocate more IT resources on Black Friday and Cyber Monday.
Step 2: Compose Business Services
In a rapidly changing IT world with microservice-based, containerized workloads, monitoring at the device level is no longer practical. Forward-looking enterprises are shifting from tracking individual IT devices and apps to a single business services view across a heterogeneous mix of clouds.
In order to quickly resolve and remediate issues unique to your business, you must first understand your business from an IT perspective.
How do you do this? Begin by defining your business services.
Because understanding which services are critical and which SLAs you are expected to meet helps you know what you need to work on first in order to remediate and eventually automate.
What is a business service?
A business service is one or more technical services that gives value to both internal and external customers. Business services should align IT assets with the needs of a company’s employee, and customers and they should support business goals— facilitating the ability of the company to be profitable. Usually, a business service includes an associated Service Level Agreement (SLA) that specifies the terms of the service.
Examples of business services include:
- Verification of internet access or website hosting
- Remote backups and remote storage
- Payroll, online trading, online banking
There are many advantages to seeing across your entire hybrid IT ecosystem with a business service view. First, your IT devices are constantly in flux—from the software updates for your applications to the number of devices using your network at any given time. But your business services are a lot more stable and long-term—changing very rarely when compared to the dynamic complexities of IT components.
Having a long-term, service-centric view across your data centers, clouds, applications, and devices, helps you understand the impact of IT on the business. A service-centric approach to IT combines different applications together into a service your business is selling to the end user. And this way you can start managing/prioritizing your work— giving you the stability to understand and learn the behavior over time.
Another advantage of having a unified, service-centric view across your IT estate is having the ability to pull in business KPIs to measure ITs impact on business outcomes.
Why is this important?
Let’s use online trading as an example. A financial institution wants to achieve a certain number of trades a day. If they are monitoring their IT at the server-or application-level—the business is unable to see the high-level impact of those trades on revenue.
A service-centric approach takes away all the minutia and noise—giving you a clear understanding of how your infrastructure is impacting the service, so you can rapidly remediate before the end-user is impacted. If/when something goes wrong anywhere in your infrastructure—which is often shared across multiple applications and business services—you can quickly identify the impact and isolate the root cause.
By shifting from device-to service-centric monitoring, you can prioritize work based on business impact.
Step 3: Add Analytics and Automation
While infrastructure monitoring is essential in order to know what you have and what it is (discovery), and accurately assess the health, availability, and risk across your complex ecosystem, forward-looking companies are now looking to automate—eliminating manual operations in order to respond proactively and reactively. Now that you have composed business services and know the most common issues affecting your most critical services, you are ready to harness the power of machine learning to gain actionable insights from your infrastructure data.
Machine learning can detect weird or anomalous service behavior and correlate those anomalies and common events within a service context. With machine learning, you can cut through the noise to quickly establish the root cause of an issue—enabling your team to keep in front of constantly changing environments.
Adding machine learning to an infrastructure monitoring tool can unlock powerful opportunities for the ITOps team.
Developing learning patterns of behavior on the service and not the individual components gives you the ability to automate the right things. What are the “right things” you should automate? Let’s start with automated ticketing and routing. Industry averages indicate manual ticket creation and routing routinely takes more than 60 minutes. You can avoid costly service impact and downtime by eliminating these time-consuming, manual activities.

You can also automate troubleshooting and remediation steps.
By automating entire workflows, such as the steps required to remotely login to a device, gather diagnostics, and diagnose or remediate a problem, you can automatically capture diagnostic data to enrich both events and incidents.
This enables faster root cause analysis and improved mean time to repair (MTTR).
If you are automating data collection, you can improve problem management, then you will be better informed about what you can resolve. And once you know the commonality in that data—through mapping and monitoring by the service (not the device)—you can automate self healing and resolution of issues. When repetitive tasks and processes are automated, ITOps teams obtain the bandwidth to do the kinds of things machines are traditionally unable to do, including creative problem solving, upgrading existing technologies, and planning for the future.
Getting Started with Hybrid Cloud Infrastructure Monitoring
The blistering rate of change in technology and customer needs is driving your business to transform from a heavily device-centric to business service centric management approach for driving intelligent automation. Traditional IT approaches are keeping IT organizations from understanding the true impact of performance issues—on customers and the business. It’s difficult to remain a leader in highly competitive markets without a clear view of the risk of changes required to deliver solutions fast enough to stay ahead of your business and customers’ expectations.
ScienceLogic offers four solutions that seamlessly adapt to your evolving IT operations’ needs. Whether you are looking to consolidate your infrastructure monitoring, automate your incidents, optimize service health for your critical applications and infrastructure, or you need to leverage machine learning to scale for growth—we’ve got you covered.
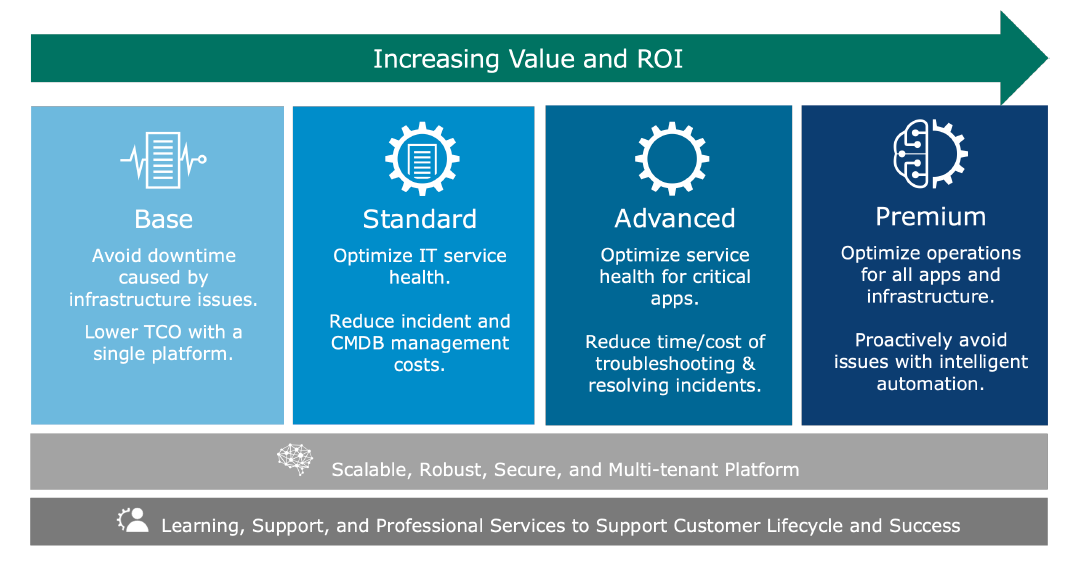
The SL1 platform will benefit and enable your ITOps team to:
- See all monitoring data in one place: With SL1, your ITOps team will be able to discover all components within your enterprise–standard and unique–across physical, virtual, and cloud. SLI provides the ability to collect and store a variety of data in a clean and normalized data lake.
- Apply machine learning for actionable insights: By adding machine learning to your tools, your team will be able to understand relationships between your infrastructure, applications, and business services, and then use this context to gain actionable insights.
- Connect your IT ecosystem: SL1 provides the ability to integrate and share data across technologies and your IT ecosystem in real-time. You can apply multi-directional integrations to automate both responsive and proactive actions at cloud scale.
ScienceLogic’s SL1: Engineered for Secure Infrastructure
Whatever your cloud strategy, and however the balance of your use of traditional on-premises IT, private cloud, and public cloud changes, you need the ability to see and monitor everything that’s going on, and more importantly, respond quickly and accurately to avert or fix service-impacting problems. The SL1 AIOps platform from ScienceLogic delivers that visibility and actionability from one place within a secure environment.

Features a virtual appliance with a built-in firewall, restricted service access, and an operating system pared down to the minimum needed.

Enables access to the API and GUI, controlled by single-sign-on and encrypts all credentials to keep them from being intercepted and used by unauthorized parties.

SL1 Is the first end-to-end infrastructure monitoring solution named on the U.S. Dept. of Defense Information Network Approved Products List.
With IT complexity growing exponentially, it’s time to rethink your infrastructure monitoring.
The SL1 platform sees everything across cloud and distributed architectures, contextualizes data through relationship mapping, and acts on this insight through integration and automation. SL1 solves the challenges and complexities of today’s IT organizations and provides the flexibility to face the monitoring and management needs of tomorrow.
Download this complimentary eBook and share with your team and start your rethinking your infrastructure monitoring today.