




AI Observability for On-Prem and Hybrid AI Factories
Companies of every size are building “AI factories” to power innovation, whether workloads run in the cloud, on-prem, or across hybrid environments. These stacks combine infrastructure, GPUs, orchestration layers, and LLMs that all need to work in sync to deliver reliable outcomes. Without visibility across the entire stack, performance drops, costs rise, and trust in AI results and projects quickly erodes. ScienceLogic delivers unified observability across every layer, so you can manage and scale AI workloads wherever they run.
Read the Gartner® Magic Quadrant™ for Observability Platforms
Observability has become mission-critical, but not all platforms are created equal. See why Gartner recognized ScienceLogic as a Visionary.
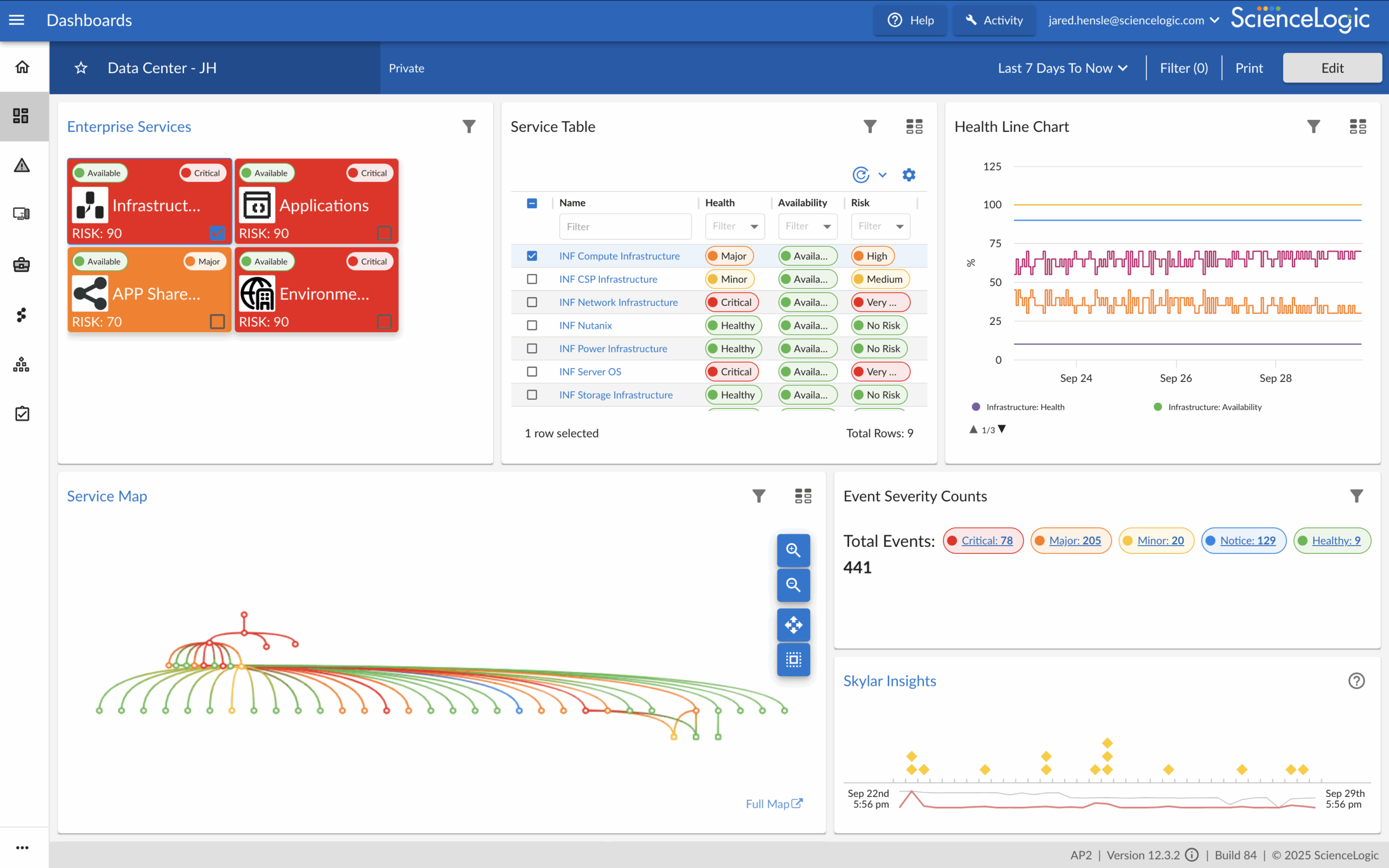
Foundation – Datacenter & Infrastructure Observability
AI workloads rely on a resilient infrastructure foundation to operate at scale. Networks, servers, and virtualization platforms are often complex, but ScienceLogic provides unified visibility across them to simplify management. By combining application, infrastructure, and service-level context, you can proactively detect risks and resolve issues before they impact performance.
- Real-time observability of Cisco, Dell, VMware, and hybrid cloud infrastructure
- Map dependencies across applications, services, and infrastructure
- Accelerate troubleshooting with Skylar AI root-cause analysis
- Prevent downtime with proactive anomaly detection
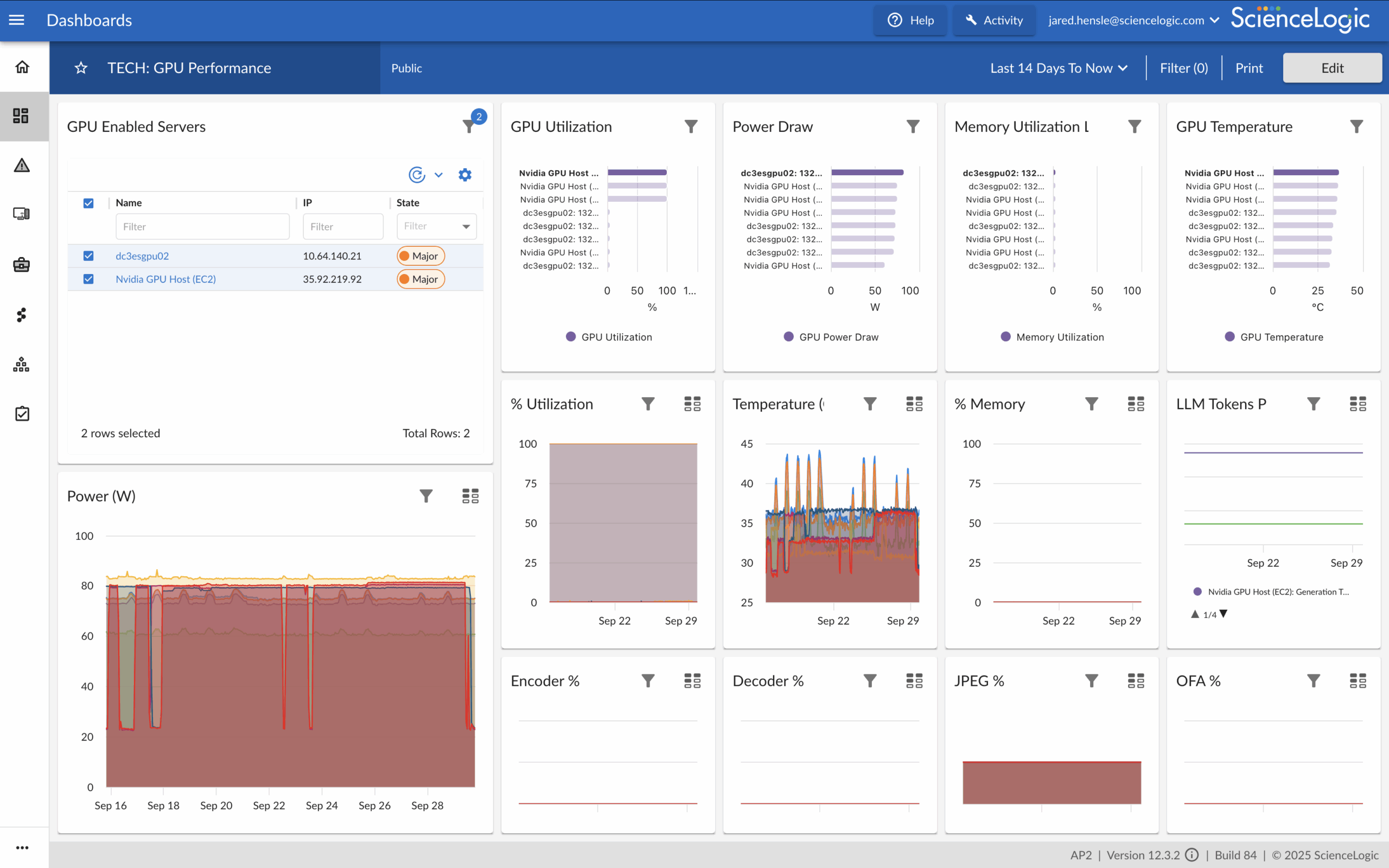
The Hardware Layer – GPUs & Environmental Sensors
GPUs are the hearts of AI, but they are costly and prone to failure without the right insights. ScienceLogic tracks GPU utilization, performance, and health metrics while correlating them to workload behavior. Combined with environmental monitoring of sensors, UPS devices, and cooling systems, you gain visibility to keep your AI infrastructure safe and efficient.
- Track AMD and NVIDIA GPU utilization, temperature, power draw, and requests
- Correlate GPU performance with application and LLM latency
- Gain visibility into UPS, cooling systems, and physical sensors for infrastructure health
- Detect and address early signs of hardware stress before outages occur
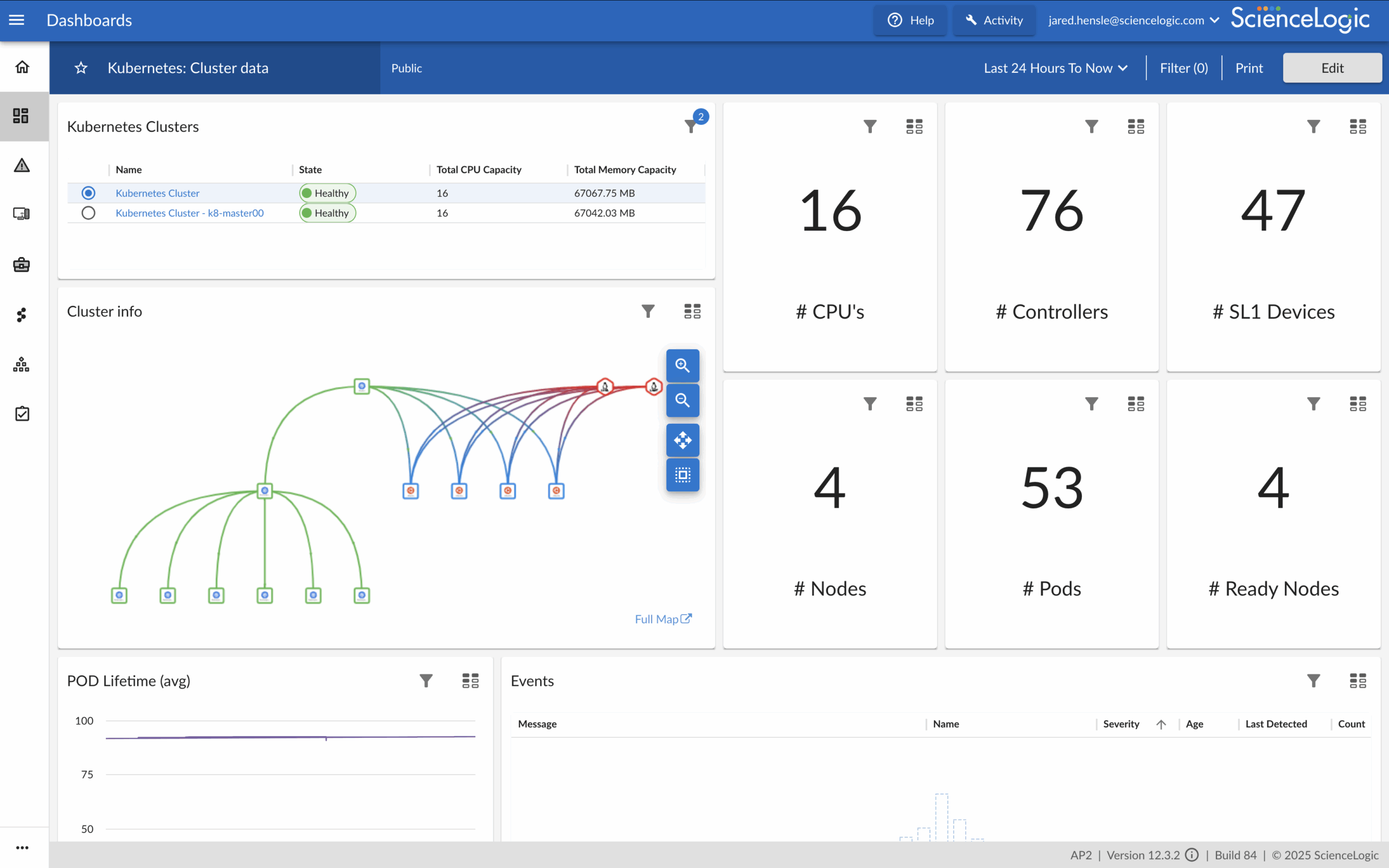
Virtualization & Containers
Virtualization and container platforms form the orchestration layer for modern AI workloads. Without observability into these dynamic environments, bottlenecks and resource constraints can quickly derail performance. ScienceLogic delivers visibility into VMware, Docker, and Kubernetes, giving teams the insights needed to align resources with demand and ensure predictable AI delivery.
- Full visibility into VMware, Docker, and Kubernetes clusters
- Detect bottlenecks in orchestration and containerized workloads
- Correlate resource usage with GPU and application performance
- Optimize resource allocation for predictable AI delivery
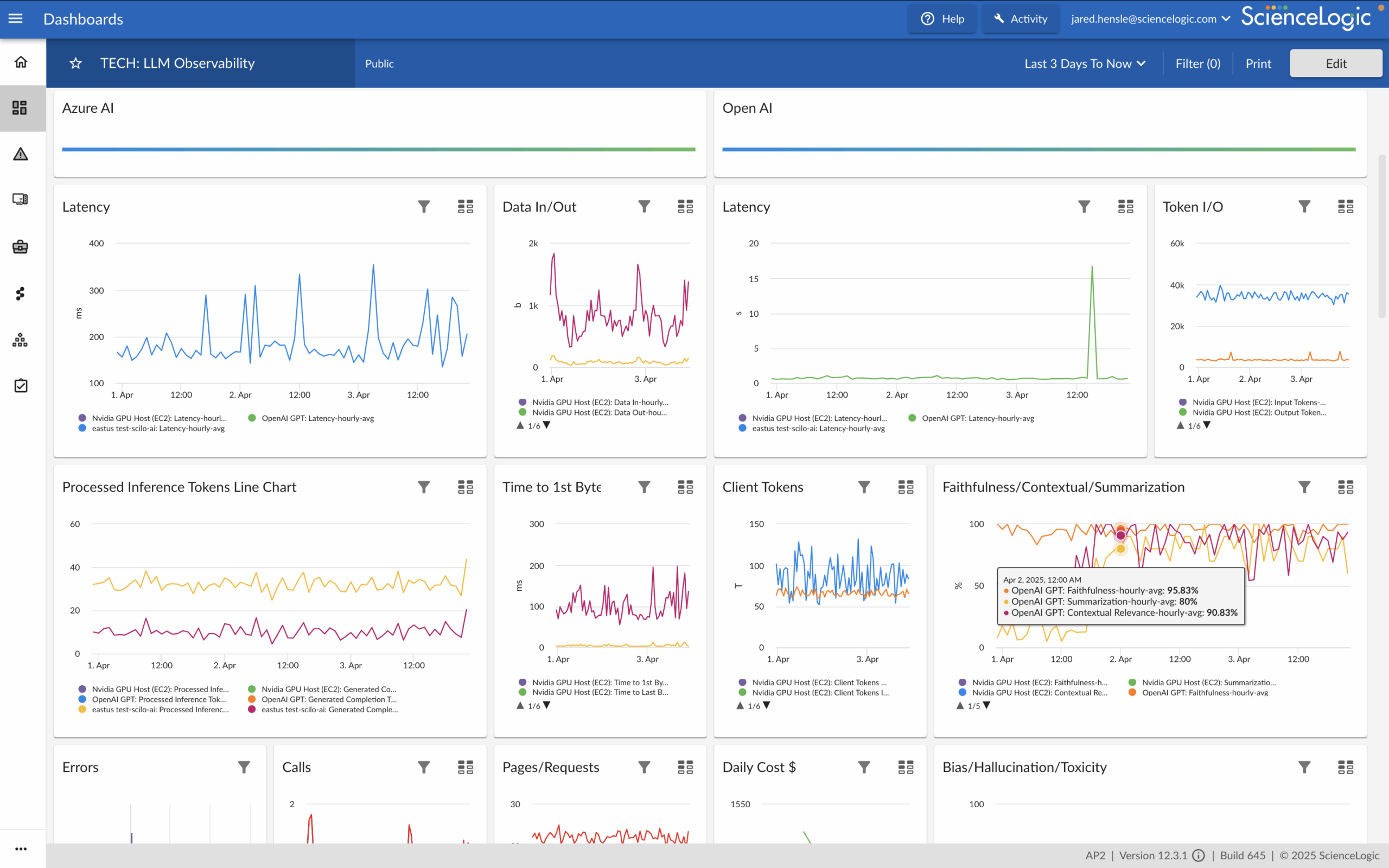
AI Model Layer & Extensibility
LLMs introduce new challenges like latency, drift, hallucination, and cost that must be tracked continuously. ScienceLogic provides observability into both private and public LLM deployments with metrics that improve trust and performance. With built-in extensibility via APIs and open standards, the platform adapts quickly to new AI tools and frameworks.
- Observe public and private LLMs such as vLLM, Azure AI, and OpenAI
- Track key signals: latency, token usage, time-to-first-byte, costs, and error rates
- Measure trust metrics like accuracy, bias, hallucination, and toxicity
- Extend observability using REST APIs and OpenMetrics (Prometheus) for niche tools
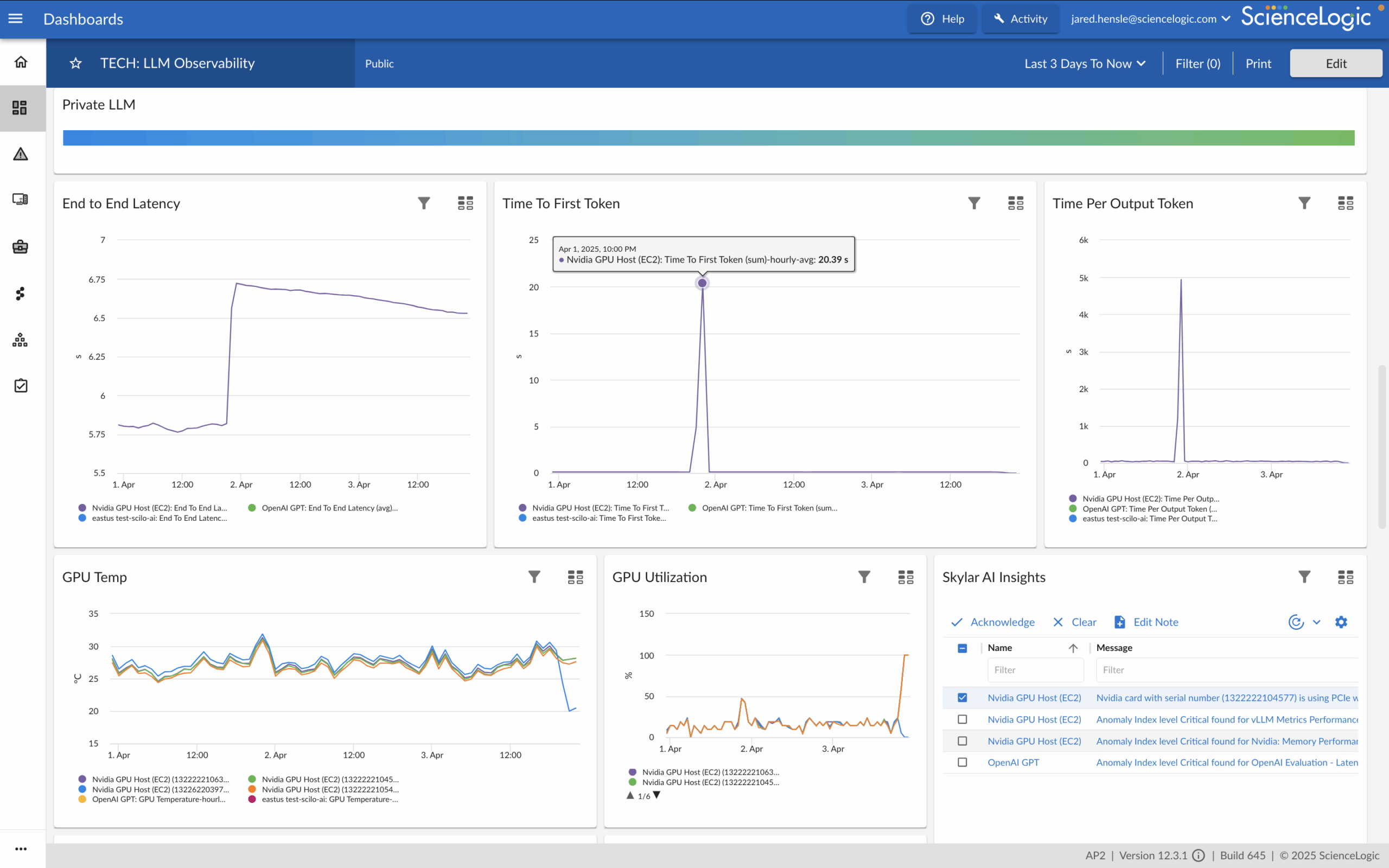
End-to-End AI Factory Visibility
Managing AI requires connecting the dots across infrastructure, hardware, orchestration, and models. ScienceLogic unifies these layers into a single correlated dashboard, eliminating guesswork and reducing mean time to resolution. Enterprises gain reliable, high-performing AI services, while MSPs can confidently package differentiated “AI factory” solutions for customers.
- Unified dashboard combining LLM performance, GPU health, and infrastructure
- Rapid root-cause insights using Skylar AI to reduce MTTR
- Ensure uptime and performance for AI workloads with real-time anomaly detection
- Create differentiated AI factory packages for customers with confidence
Ready to See More?
Gain end-to-end visibility for every workload from infrastructure to GPUs and LLMs with the ScienceLogic AI Platform. Fill out the form to request a custom demo to see it in action.